废话不多说,我们直接开整。首先需要导入需要的类库,相关内容我会在后续代码中进行详细介绍。
from keras.datasets import mnist
from keras.utils import to_categorical
from keras import models,layers,regularizers
from keras.optimizers import RMSprop
数据集为MNIST 手写字符数据集,训练集为 60,000 张 28x28 像素灰度图像,测试集为 10,000 同规格图像,总共 10 类数字标签。
1、用法
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
返回2 个元组:
- x_train, x_test: 分别表示训练集与测试集的图片。
- y_train, y_test: 分别表示训练集与测试集的数字标签(范围在 0-9 之间的整数)。
2、下载数据集
根据上述用法我们可以直接将这个数据集下载下来。
#加载数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
3、展平矩阵
通过上述介绍我们知道,每张图片其实是一个2828的数字矩阵,矩阵中的每个数字(0-255)代表着该像素点的灰度级。为了可以更方便的对其进行操作,我们将其变为一个一维的向量(7841),即将这个数字矩阵展平,将这个正方形变为一个宽为1的长方形。astype方法用来转换数据类型。
#展平
train_images = train_images.reshape((60000, 28*28)).astype('float')
test_images = test_images.reshape((10000, 28*28)).astype('float')
4、采用one-hot编码
one-hot编码是在深度学习中非常常见的一种编码方式,使用它的目的就是为了能够让各种变量转换为可以被各种算法利用的形式。将离散型特征使用one-hot编码还会让各个特征之间的距离更加的合理。举个例子,若用1来表示狗,2来表示猫,3来表示老鼠。则猫狗之间的距离为1,鼠狗之间的距离为2,但是猫狗之间的差别真的就小于鼠狗之间的差别吗?这种差别又以什么来作为标准呢?所以采用one-hot编码,以[1,0,0]表示狗,[0,1,0]表示猫,[0,0,1]来表示老鼠就不会出现这种情况。
这里用to_categorical方法来对十种数字进行编码。例如,数字3的编码方式为:[0,0,0,1,0,0,0,0,0,0,0]
#将标签以onehot编码
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
5、建立模型
这里需要用到Sequential 顺序模型,该模型是多个网络层的线性堆叠。我们可以简单地使用 .add() 方法将各层添加到模型中。在这里需要注意的是顺序模型中的第一层(且只有第一层,因为下面的层可以自动地推断尺寸)需要接收关于其输入尺寸的信息。
#建立模型
network = models.Sequential()
#kernel_regularizer正则化降低过拟合
network.add(layers.Dense(units=128, activation='relu', input_shape=(28*28, ), kernel_regularizer=regularizers.l1(0.0001)))
#drout层降低过拟合
network.add(layers.Dropout(0.01))
network.add(layers.Dense(units=32, activation='relu', kernel_regularizer=regularizers.l1(0.0001)))
network.add(layers.Dropout(0.01))
network.add(layers.Dense(units=10, activation='softmax'))
6、编译与训练
通过对模型设置一些超参数来尽可能的使模型达到最优。
#编译
network.compile(optimizer=RMSprop(learning_rate=0.001), loss='categorical_crossentropy', metrics=['accuracy'])
#训练
network.fit(train_images, train_labels, epochs=20, batch_size=128, verbose=2)
7、在测试集上测试性能
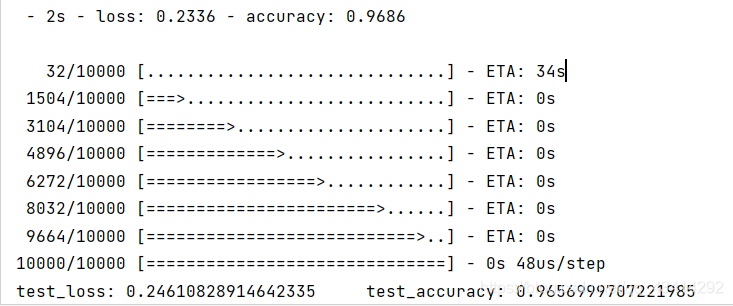
训练模型最终的目的是为了预测,通过训练模型已经能够在训练集上达到不错的效果,现在为了检验在测试集上它的表现如何,采用evaluate方法返回模型的误差值和评估标准值。
#在测试集上测试模型性能
test_loss, test_accuracy = network.evaluate(test_images, test_labels)
print("test_loss:", test_loss, " test_accuracy:", test_accuracy)
最后附上完整代码:
from keras.datasets import mnist
import matplotlib.pyplot as plt
from keras.utils import to_categorical
from keras import models,layers,regularizers
from keras.optimizers import RMSprop
#加载数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# print(train_images.shape, test_images.shape)
# print(train_images[0])
# print(train_labels[0])
# plt.imshow(train_images[0])
# plt.show()
#展平
train_images = train_images.reshape((60000, 28*28)).astype('float')
test_images = test_images.reshape((10000, 28*28)).astype('float')
#将标签以onehot编码
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# print(train_labels[0])
#建立模型
network = models.Sequential()
#kernel_regularizer正则化降低过拟合
network.add(layers.Dense(units=128, activation='relu', input_shape=(28*28, ), kernel_regularizer=regularizers.l1(0.0001)))
#drout层降低过拟合
network.add(layers.Dropout(0.01))
network.add(layers.Dense(units=32, activation='relu', kernel_regularizer=regularizers.l1(0.0001)))
network.add(layers.Dropout(0.01))
network.add(layers.Dense(units=10, activation='softmax'))
#编译
network.compile(optimizer=RMSprop(learning_rate=0.001), loss='categorical_crossentropy', metrics=['accuracy'])
#训练
network.fit(train_images, train_labels, epochs=20, batch_size=128, verbose=2)
#在测试集上测试模型性能
# y_pre = network.predict(test_images[:5])
# print(y_pre, test_labels[:5])
test_loss, test_accuracy = network.evaluate(test_images, test_labels)
print("test_loss:", test_loss, " test_accuracy:", test_accuracy)
本次实战是参照b站大佬敲出来的,大佬讲的很详细,需要的小伙伴可以来看一下,地址我贴在在这里了 传送门
因为搭建的网络较为简单,所以准确率没有那么高。