1.Title
ECAPA-TDNN Emphasized Channel Attention, Propagation and Aggregation
2.Summary
本文提出的ECAPA-TDNN是一个基于TDNN的说话人嵌入提取器,主要用于说话人验证。在原有x-vector架构的基础上,进一步加强了通道注意(使网络只关注它认为重要的帧)、特征聚集和传播的能力(利用残差连接收集浅层特征)。
3.Research Objective
说话人验证
4.Problem Statement
x-vector存在一些局限性
作者在ECAPA-TDNN架构中纳入了潜在的解决方案。
5.Method(s)
1. Channel- and context-dependent statistics pooling
将时间注意力机制进一步扩展到通道维度可能是有益的,这使网络能够更多地关注那些不在相同或相似的时间实例上激活的说话人特征。
2. 1-Dimensional Squeeze-Excitation Res2Blocks
提出ECAPA-TDNN架构的SE-Res2Block,模型结构如下: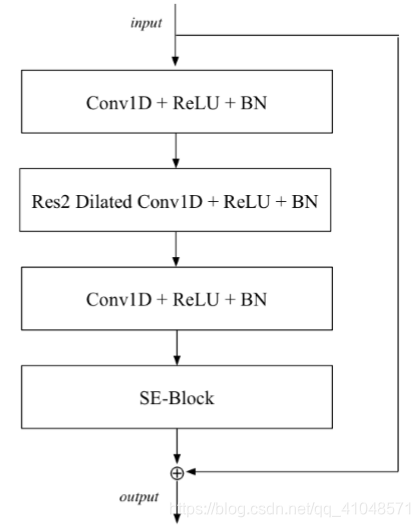
它能够通过在内部构建层次化的残差连接来处理多尺度特征。这个模块的整合提高了性能,同时大大减少了模型参数的数量。
3. Multi-layer feature aggregation and summation
作者认为更加浅层的特征图也可以用于说话人特征的提取,所以将所有SE-Res2Block的输出特征图连接起来进行多层特征的聚合,模型结构如下: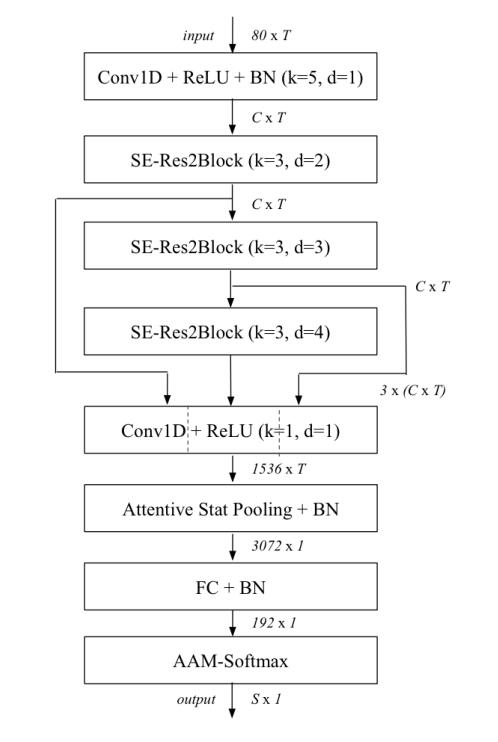
6.Evaluation
该系统采用EER和MinDCF来进行评估
7.Conclusion
在VoxCeleb和VoxSRC 2019评估集上,EER有比baseline平均19%的相对改进。
8.Notes
8.1 TDNN
TDNN相当于一维CNN,它的共享权重被限制在单一的维度上,没有池化层,适用于语音和时间序列的信号处理。

以上为TDNN网络结构模型,其中各色线的权重相同,相当于把权重延时。隐藏层和输出层之间也可以采用该方法,这样整体的权重就大大减少。便于训练。而xvector是基于TDNN结构的,大致相似,故这里再不做过多介绍。
TDNN网络优点:
- 网络是多层的,每层对特征有较强的抽象能力(感觉现在网络大部分层数都很深,所以觉得这也不算个优点)
- 能表达语音特征在时间上的关系(在送入隐藏层时根据时延大小送入多帧)
- 权值具有时间不变性(训练快)
- 学习过程中不要求对所学的标记进行精确的时间定位 !!!(不懂)
- 通过共享权值,方便学习
8.2 SE-BLOCK
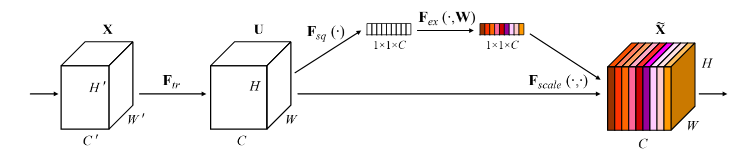
以上为SE模块的结构图,可以看到它主要分为三个部分:压缩、激励、和Scale操作。
- 压缩:这里采用了一个平均池化,将特征的维度从W×H×C压缩到了1×1×C。H和W压缩成一维后,相当于这一维参数获得了之前H×W全局的视野,感受区域更广。
- 激励:这里又加入了全连接层对每个通道的重要性进行预测,得到不同channel的重要性大小后再作用到之前的feature map的对应channel上,再进行后续操作。
- Scale操作:在得到1×1×C向量之后,就可以对原来的特征图进行scale操作了。很简单, 就是通道权重相乘, 原有特征向量为W×H×C, 将SE模块计算出来的各通道权重值分别和原特征图对应通道的二维矩阵相乘 ,得出的结果输出。
总结:SE模块主要为了提升模型对channel特征的敏感性,这个模块是轻量级的,而且可以应用在现有的网络结构中,只需要增加较少的计算量就可以带来性能的提升。
8.3 Aggregate and Propagate features
- Aggregate:类似CNN中的convolution,就是用周边节点的feature更新下一层的hidden feature。对应到卷积中感觉就像是利用卷积核不断地把特征聚集到一起。
- Propagate:暂时理解为特征经过不断处理后的层层递进。
8.4 Bottleneck layer
Bottleneck layer又称之为瓶颈层,使用的是1*1的卷积神经网络。之所以称之为瓶颈层,是因为长得比较像一个瓶颈。
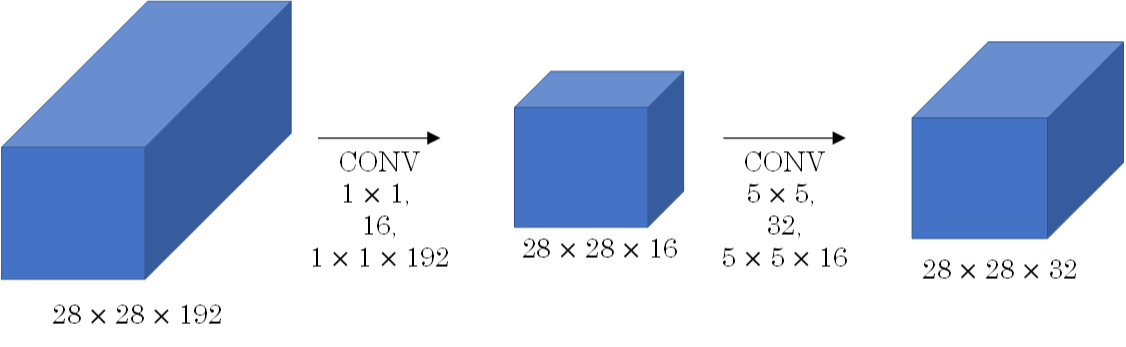
如上图所示,经过 1×1 的网络,中间那个看起来比较细。像一个瓶颈一样。使用 1×1 网络的一大好处就是可以大幅减少计算量。
8.5 余弦距离
余弦距离(Cosine Distance)也可以叫余弦相似度。 几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。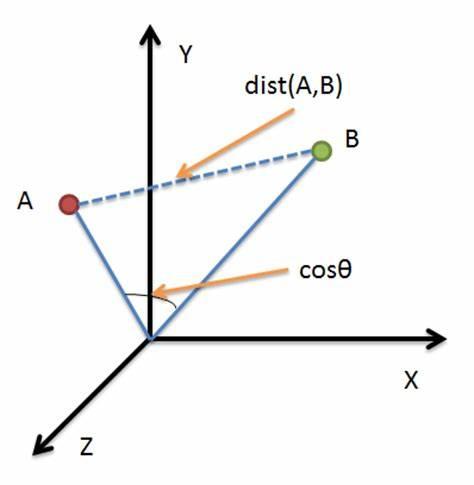
余弦取值范围为[ − 1 , 1 ] [-1,1][−1,1],求得两个向量的夹角,并得出夹角对应的余弦值,此余弦值就可以用来表示这两个向量的相似性。夹角越小,趋近于0度,余弦值越接近于1,它们的方向更加吻合,则越相似;当两个向量的方向完全相反夹角余弦取最小值-1;当余弦值为0时,两向量正交,夹角为90度。余弦相似度与向量的幅值无关,只与向量的方向相关。
这里有一个疑问:余弦距离的这种比较方法和那种既比较方向又比较长度的方法有什么差异?
8.6 statistics pooling layer
首先需要知道池化层(pooling layer)的作用:
- 池化是缩小高、长方向上的空间的 运算 。池化层是具有这种功能的一个深度学习的层
- 对输入的特征图进行 压缩 ,一方面使特征图变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征
而statistics pooling layer的作用也是相似的,只不过采用的中间算法略有不同。
8.7 VAD(Voice Activity Detection)
语音活性检测 (Voice activity detection,VAD), 也称为 speech activity detection or speech detection, 是一项用于语音处理的技术,目的是检测语音信号是否存在。
8.8 空洞卷积(Dilated Convolution)
Dilated Convolution(空洞卷积/膨胀卷积)是在标准的 convolution map 里注入空洞,以此来扩大感受野。空洞卷积与普通的卷积相比:除了卷积核的大小以外,还有一个扩张率(dilation rate)参数,主要用来表示膨胀的大小。在普通卷积中,可以认为它的dilated rate = 1。
适用情况:在图像需要全局信息、语音文本需要较长的sequence信息依赖的问题。
对比传统卷积,空洞卷积的感受野是呈指数级别的增长,例如下图对比:
- 传统卷积

- 空洞卷积

那为什么要增大感受野呢?
感受野的定义为经过卷积后对应区域的大小,为了保证所利用的信息是全局的,不仅仅是局部信息,我们应该去增大感受野。但是这里还存在一些问题:
- 空洞卷积中间有一部分为空的,所以它一定会丢失一部分信息
- 需要更具处理对象尺寸大小来选择合适的dilation rate
8.9 BatchNormal(批正则化)
- 为什么要引入批正则化?
因为每一批的数据的数据分布会有差别,为了能够使每一批的数据分布相同,所以才要进行批归一化。
- 批正则化的优缺点:
- 优点:能够使得每批的数据分布一致,同时能够避免梯度消失
- 缺点:
- 当批的大小较小时,计算得到的均值和方差不准确,使归一化的效果变差,导致模型的性能下降
- 当批的大小较大时,内存可能不足



