1.Title
In defence of metric learning for speaker recognition
2.Summary
在本文中,作者对VoxCeleb数据集上最流行的说话人识别损失函数进行了广泛评估。感觉创新不是很够,只是任务量很足。光跑代码的时间就花了两年多一点。
3.Research Objective
- vanilla triplet 损失函数与基于分类的损失函数相比更有竞争性。
- 作者提出的度量学习训练的网络优于目前最先进的方法。
4.Problem Statement
解决对从未见过的说话人进行开放集识别,使最终的嵌入能够将信息浓缩到一个紧凑的语料级表示中,使其在相同说话人中有较小的距离,在不同说话人中有较大的距离。这也是度量学习的目标。
5.Method(s)
在相同条件下比较不同损失函数的性能。
6.Evaluation
无
7.Conclusion
GE2E和原型网络显示出优于流行的基于分类的方法的性能。
8.Notes
8.1 度量学习
度量学习又叫做相似度学习,其基本原理是根据不同的任务来自主学习出针对某个特定任务的度量距离函数。比如在一个分类任务中,当我们拿到目标的特征后,通过某种方法得到向量间的距离,通过函数进行优化,将距离小(特征相近)的目标拉近,距离大(特征不相近)的目标拉远。这就是一个度量学习的过程。
8.2 损失函数
什么是损失函数?
损失函数(loss function)就是用来度量模型的预测值f(x)与真实值Y的差异程度的运算函数,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
为什么要用损失函数?
损失函数使用主要是在模型的训练阶段,每个批次的训练数据送入模型后,通过前向传播输出预测值,然后损失函数会计算出预测值和真实值之间的差异值,也就是损失值。得到损失值之后,模型通过反向传播去更新各个参数,来降低真实值与预测值之间的损失,使得模型生成的预测值往真实值方向靠拢,从而达到学习的目的。
softmax
- softmax损失函数的本质是将一个k维的任意实数向量x映射成另一个k维的实数向量,其中,输出向量中的每个元素的取值范围都是(0,1),即softmax损失函数输出每个类别的预测概率。
- softmax损失函数具有类间可分性,被广泛用于分类、分割、人脸识别、图像自动标注和人脸验证等问题中,其特点是类间距离的优化效果非常好,但类内距离的优化效果比较差。因此它常与对比损失或中心损失组合使用(本文提到它常与PLDA结合使用),以增强区分能力。
本文中的几种损失函数
- triplet loss:
- triplet:一个三元组,这个三元组是这样构成的:从训练数据集中随机选一个样本,该样本称为Anchor,然后再随机选取一个和Anchor (记为x_a)属于同一类的样本和不同类的样本,这两个样本对应的称为Positive (记为x_p)和Negative (记为x_n),由此构成一个三元组。
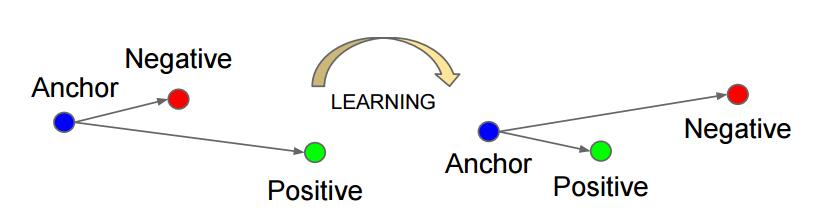
- triplet loss:针对三元组中的每个元素(样本),训练一个参数共享或者不共享的网络,得到三个元素的特征表达,分别记为:f(x_a)、f(x_p)、f(x_n)。通过学习,让x_a和x_p特征表达之间的距离尽可能小,而x_a和x_n的特征表达之间的距离尽可能大,并且要让x_a与x_n之间的距离和x_a与x_p之间的距离之间有一个最小的间隔。
- triplet:一个三元组,这个三元组是这样构成的:从训练数据集中随机选一个样本,该样本称为Anchor,然后再随机选取一个和Anchor (记为x_a)属于同一类的样本和不同类的样本,这两个样本对应的称为Positive (记为x_p)和Negative (记为x_n),由此构成一个三元组。
- GE2E:没看太懂,尬了。
- GE2E loss包含softmax和contrast两种具体形式,每种形式的目标不仅仅是增大样本与所属说话人中心的cosine得分,同时减小样本与非所属说话人中心cosine得分。
- GE2E计算consine得分时,采用相似矩阵计算形式,一次性计算所有consine得分,相比TE2T,可显著加速计算



