文章链接:https://arxiv.org/pdf/2110.03869.pdf
1.题目
SELF-SUPERVISED SPEAKER RECOGNITION WITH LOSS-GATED LEARNING
2.总结
写完笔记之后最后填,概述文章的内容,以后查阅笔记的时候先看这一段。
3.研究动机
在自监督说话人识别中,使用伪标签作为监督信息对模型有着积极的效果。然而,现有研究发现,不是所有的伪标签都对模型有着积极的效果。且作者发现可靠的伪标签相比于不可靠的伪标签在网络建模时有着更快的速度。
4.使用方法
模型采用了一种two-stage的架构,如下图所示。
- StageⅠ采用对比学习训练来得到一个说话人编码器
- StageⅡ首先通过聚类生成伪标签,然后反复训练分类网络
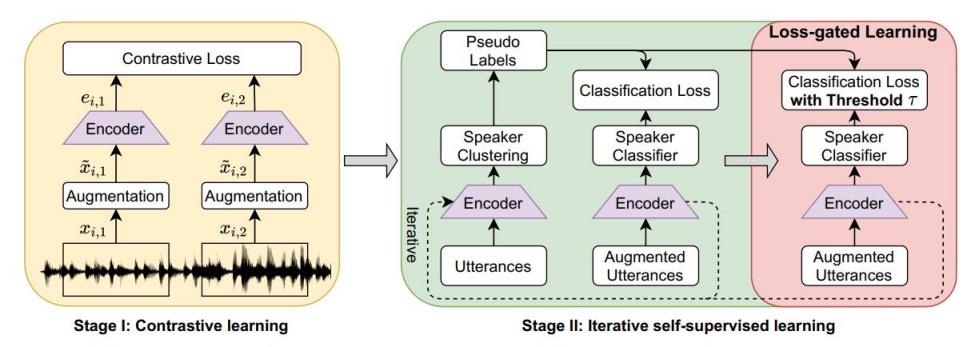
4.1 StageⅠ
StageⅠ采用了对比学习的方法来训练说话人编码器。这里需要注意的是本文中的positive pairs定义为来自于同一段语音的segments(即同一段语音被分割后的两段),negative pairs则是来自不同语音的segments。
这里其实对于对比学习还是依旧存在一点疑问,按照对比学习的方法,从同一个说话人的不同语音段分割出来的语音是属于negative pairs,这里让人感觉很别扭。博主查了一些相关资料,大致是这样解释的:对比学习的目的是判断是否是正负样本,本质上一个二分类的问题。它是在训练网络提取特征的能力(提取某一类型数据的通用特征),而并非有确切的目的(分类、分割、检测等)。当在没有标签的条件下得到一个不错的编码器之后,可以加上不同的任务头进一步去做下游任务,对应在本文中也就是StageⅡ阶段。
4.2 StageⅡ
首先,StageⅡ使用StageⅠ训练好的编码器作为initial model提取说话人特征;然后,使用k-means聚类算法对这些说话人特征进行聚类以生成伪标签,在这里作者假设聚类后的每一个簇表示同一个说话人;接着,再用生成的伪标签训练编码器;最后,经过不断迭代直到模型收敛。这里需要注意的是每次迭代得到的分类编码器会生成新的伪标签,用于下一次迭代训练。
4.3 LOSS-GATED LEARNING
5.结论
- 可靠的伪标签相比于不可靠的伪标签在网络建模时有着更快的速度
- LGL策略可以有效选择可靠伪标签