1.Title
Attentive Feature Fusion for Robust Speaker Verification
2.Summary
本文提出了一种基于注意力机制的动态权重融合方法AFF,并将其应用到了ResNet上,实验结果证明了该方法的有效性。它可以在提升少部分参数量的情况下,利用注意力机制挖掘出更好的特征,从而使模型达到一个更好的效果
3.Research Objective
目前大部分特征融合策略采用的是相加或拼接的方式,而两种方式都是固定且没有学习能力的(这里我的理解是作者想把特征也当成权重来进行训练),这在一定程度上缺少了特征之间的交互。因此作者在现有模型上采用新的特征,从而提升模型效果。
4.Method(s)
通过注意力机制来对提取到的特征做进一步的细化,如下图: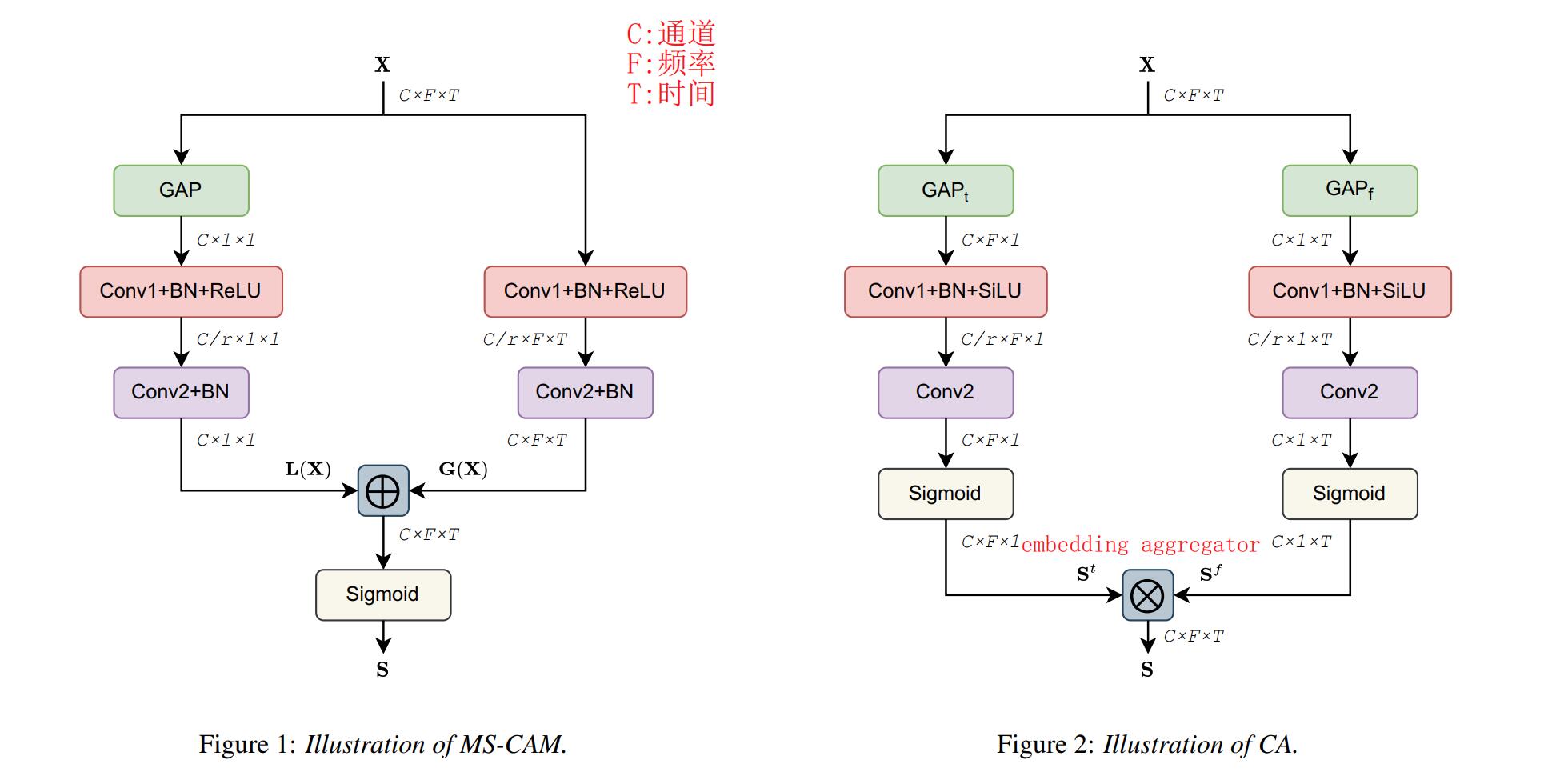
可以看到,左图是将特征分为C(通道)和F(频率)、T(时间)两路,仅仅对通道做了全局池化后经过一系列卷积等操作后得到注意力图。右图则是将F(频率)和T(时间)各分两路进行类似的处理,处理更为细致,后面的实验结果也表明,CA的效果要比CAM略好一些。
而后作者将AAF应用到了残差网络当中,如下图: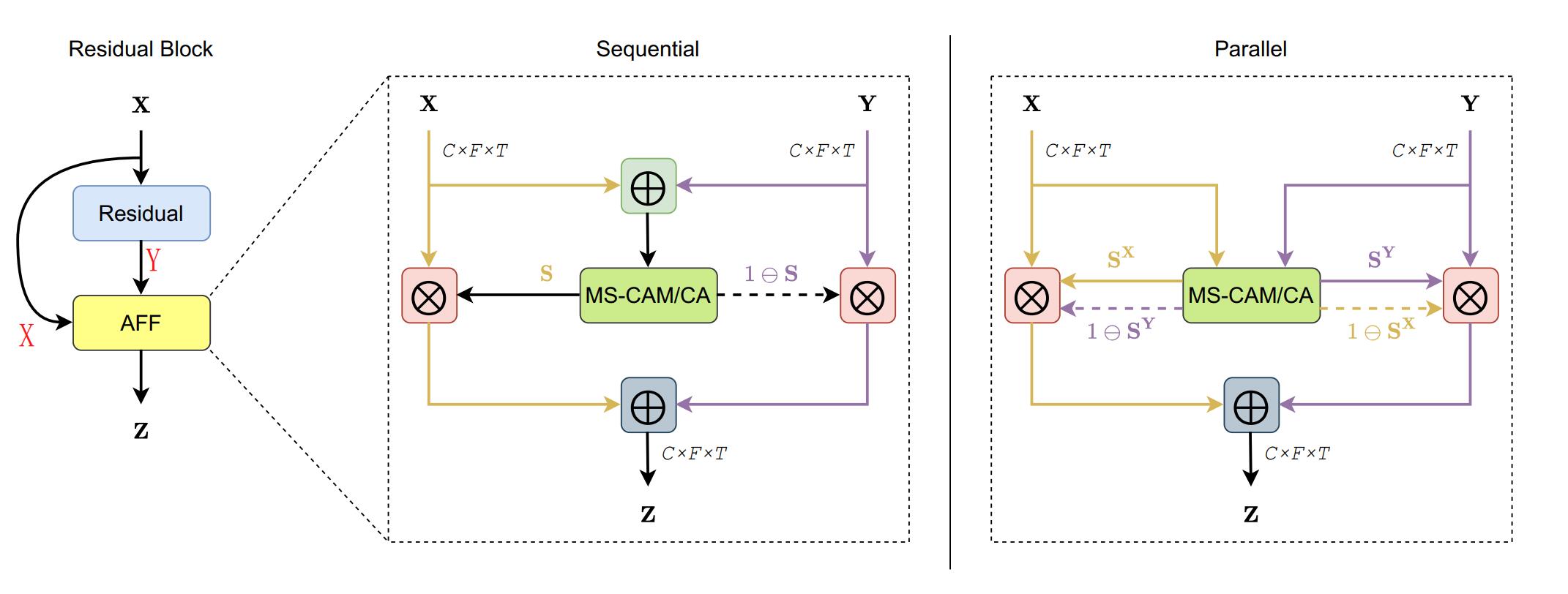
其中有两种不同的方式:
- Sequential:先整体融合,进入MS-CAM/CA后再分开融合。
- Parallel:兵分两路进入MS-CAM/CA分开融合。
注意:虽然说有时序和并行两种方式,但如果看整体的话其实它们都还是一个串行结构。
5.Evaluation
本文中提出的特征融合方案包括时序AFF和并行AFF,实验中证明它们可以有效代替传统的特征融合,并且这两种方案是动态可学习的。将其应用到一些baseline上可以显著提高模型的效果,唯一美中不足的是它还会轻微地提升模型参数量。
6.Conclusion
作者有提到在说话人验证(SV)任务中,一些论文证明了分析特征的时域和频域特征是非常有必要的,我们不应该去平等的对待它们。由此也验证了本文中CA会比CAM效果好。
7.Notes
7.1 x-vector
x-vector可接受任意长度的输入,转化为固定长度的特征表达。此外,在训练中引入了包含噪声和混响在内的数据增强策略,使得模型对于噪声和混响等干扰更加具有鲁棒性。
x-vector包含多层帧级别的TDNN层,一个统计池化层和两层句子级别的全连接层,以及一层softmax。其模型如下图: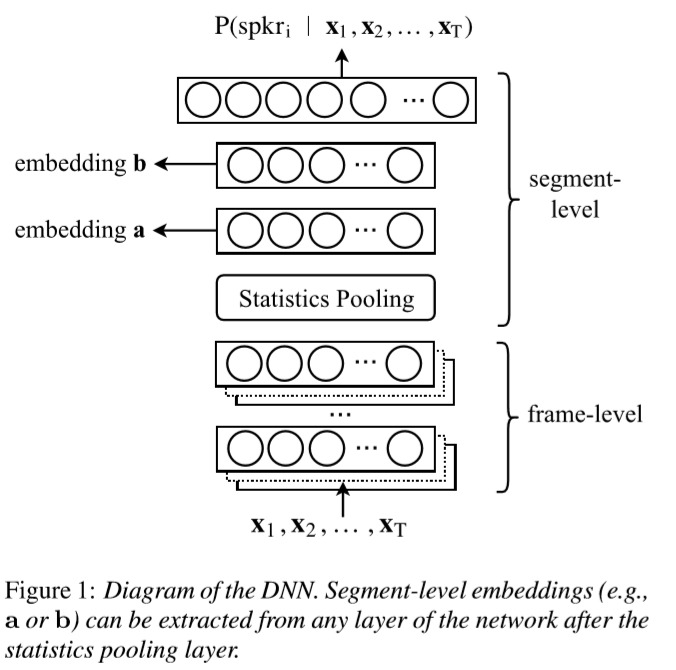
其中统计池化层是将前两层TDNN的输出结果池化后拼接起来得到句子级别的特征表达。图中的a和b分别为3秒滑动窗口的均值归一化和SAD,最后再经过一个softmax来输出说话热概率。
x-vector的优势:
- 参数少,便于训练,收敛速度快
- 抽取特征的能力强
- 鲁棒性更强
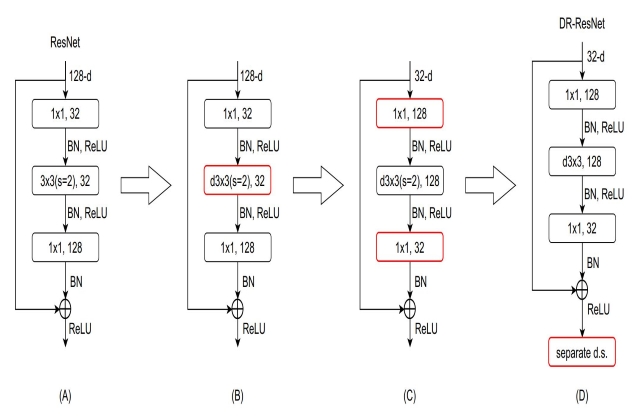
7.2 ResNet
ResNet是在2015年由何凯明提出的一种网络,该网络具有超级深的网络层数、新提出的残差模块。
在ResNet提出之前,所有网络都是由卷积层和池化层通过不同方法叠加而成的。一般来说,一个网络越深,越能提取到更深层次的特征,学习的效果也会越来越好。但是后来人们发现,当网络层数超过一定的层数后,网络会出现梯度消失、梯度爆炸以及退化现象。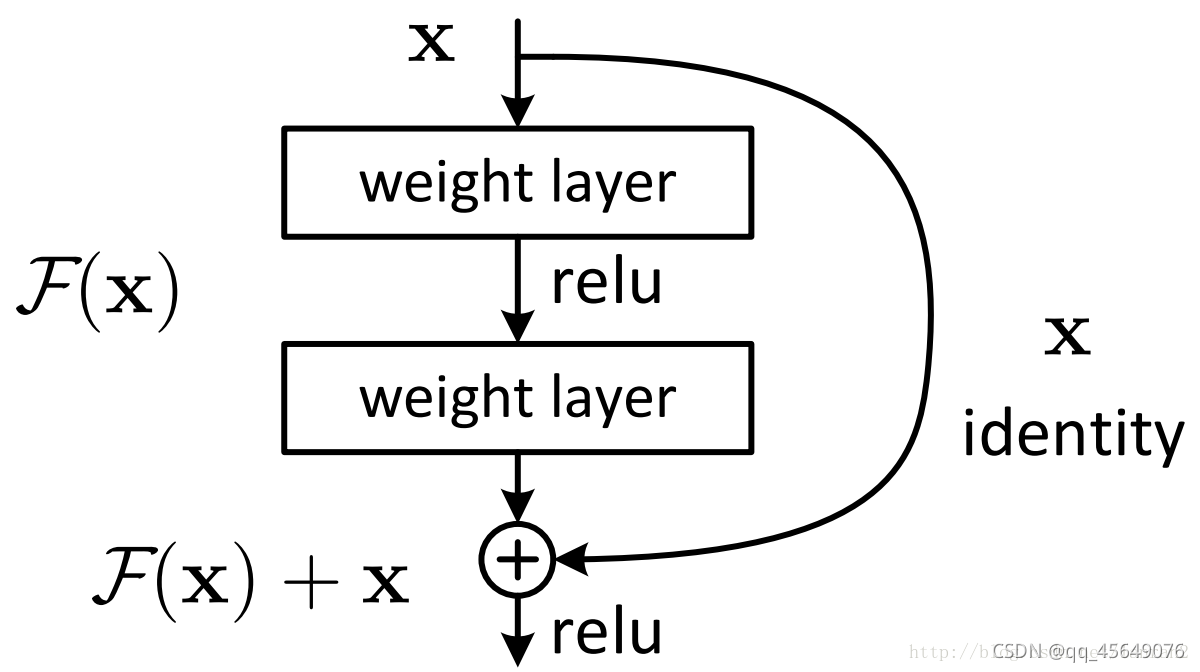
7.3 MFCC与Fbank
本文中所用的初始特征为Fbank,在在语音相关的任务中最常用的特征就是MFCC和Fbank。
- Fbank(Fileter Bank):人耳对声音频谱的响应是非线性的,Fbank就是一种前端处理算法,以类似于人耳的方式对音频进行处理,可以提高语音识别的性能。
- MFCC(Mel-frequency cepstral coefficients):梅尔频率倒谱系数。梅尔频率是基于人耳听觉特性提出来的, 它与Hz频率成非线性对应关系。梅尔频率倒谱系数(MFCC)则是利用它们之间的这种关系,计算得到的Hz频谱特征。主要用于语音数据特征提取和降低运算维度。